There is an interesting post in rastergrid.com from 2010 about this topic.
However, I haven’t found on the Internet more information about it; so I thought I should blog about it. Every now and then I see this question pop up over and over again on GameDev.Net.
Note that this post applies to both Direct3D and OpenGL, with the most notable difference that D3D forces all UBOs (const buffers in D3D jargon) to be of a maximum and guaranteed minimum 64kb (unless you’re running on D3D11.1 on Windows 8.1); while GL guarantees a minimum of only 16kb (which is weird, considering D3D guarantees 64kb) and there is no upper limit.
UBOs (Uniform Buffer Objects) are called const buffers in D3D, and TBO (Texture Buffer Objects) are called texture buffers in D3D
Once upon a time…
Once upon a time, UBOs were described of at least 16kb in size (typically 64kb), preferred for small data with locality; built for sequential access. i.e. If you access data[i]; make sure ‘i’ always stays the same or goes from 0 to 16 or any range but always in the same order, never random across the same group of pixels being processed, to avoid divergency.
While TBOs are at least 128MB in size and suited for large data and random access.
Well… in GCN (Graphics Core Next, aka Radeon HD 7000 onwards) at the hardware level they’re basically the same thing.
There is no difference between UBOs and TBOs. If the TBO is very small, it will fit in the L1 and L2 caches. Just like an UBO. The only difference will be the GLSL syntax used and the API calls used to bind the BO. It isn’t surprising that at the time of writing the driver for GCN devices reports GL_MAX_UNIFORM_BLOCK_SIZE as 2GB (whereas other hardware reports the usual 64kb).
However, take in mind the driver may compile GLSL differently since UBOs have a lot of assumptions that are suitable for performance.
What happened between UBOs and TBOs?
Waaay back in 2006; UBOs would be stored in so-called constant registers. As in, real registers. DX9 GPUs have 256 registers (128-bit wide; 4 floats); while some DX10 GPUs had 4096 of those.
If two pixels were being processed by the same warp; they better index the same constant, so that they would both use the same register. Otherwise, the GPU would have to reorder its scheduling so that it could run twice, once for each different register; then mask the result.
This was very expensive and known as “shader constant waterfalling”; hence the “sequential access” property of UBOs. And due to the limited amount of constant registers, they would be limited to exactly 64kb.
In modern day GPUs, UBOs are stored in RAM or in caches, hence shader constant waterfalling doesn’t happen anymore; and TBOs may completely live in the cache if they’re small enough, just like an UBO. And if the UBO is large enough, it wouldn’t fit in the cache and be fetch from RAM, just like the TBO.
Hence at the hardware level, the lines between TBOs and UBOs started to blur. And that’s because this is starting to heavily resemble how a CPU works.
Old days: Shader constant waterfalling
As the section above indicates, this is no longer an issue in modern hardware. However it’s useful to know what it was and how old hardware worked, so that certain bits of the OpenGL spec can be understood.
Indexing a uniform array meant indexing a constant register. There is no such analog thing in the CPU. This means that given “float myValues[2];”; in order to index myValues[0] and myValues[1]; we need to address constant registers c0 and c1.
But constant registers are 128-bit wide. This means that internally what happens is: “vec4 myValues[2];” and then we address “myValues[0].x” and “myValues[1].x”; that is, we waste yzw from both registers.
This gives us the first origin of an OpenGL oddity: The infamous rule #3 from the std140 uniform layout. It basically causes almost everything to end up being promoted to a vec4 padding or alignment; it’s a big source of confussion and many drivers get it wrong when complex structure declarations are involved, so wrong in fact, that it is easier to just declare all your members as vec4 and use the swizzles yourself manually; rather than expecting the driver to get the alignment of non-vec4 members right (also there’s a big chance you got the rules wrong).
Of course, for modern hardware, this rule is overly exaggerated. Because data is fetched from hardware. std430 layout in fact reflects this. But unfortunately std430 can’t be used with UBOs, and only with SSBOs.
The second problem was dynamic indexing. As long as all threads inside the warp index the same register (they’re not divergent), they can run the same code.
But when thread A indexes one register, and thread B indexes a different register; they must run different code. This isn’t just your typical branch divergency that GPUs usually deal with. The threads must execute different code; since they need to access different registers. The GPU must halt its shader execution, and patch the assembly exclusively for this warp on the fly. Or perform a synchronization every time the constants are accessed and decide what to access on the fly. The specifics on how the hardware handled SCW stalls varies depending on device and could be trade secret. Either way, it’s not pretty.
The most common example of dynamic indexing is hardware skinning; as each vertex has its own bone ID, which corresponds to a matrix. For very complex models (lots of vertices, >50 bones), TBOs would scale better than UBOs due to constant waterfalling; whereas the difference would be negligible for simple models.
Fortunately, this isn’t a problem anymore in any of the modern hardware from all three major vendors. If anyone tells you that UBOs aren’t good for random memory accesses and that you should be using TBOs, their knowledge is outdated.
So… UBO or TBO. They’re the same then?
Not quite.
For AMD GCN:
For the GCN (Graphics Core Next) architecture, the difference is that an UBO is a “typed buffer”, whereas a TBO is an “untyped buffer”.
Typed buffers must declare the data format in the instruction, i.e. the instruction specifies whether we’re reading a float, an int, a 16-bit float (half), etc. UBO’s data format is known beforehand (it’s always either a float, an int or a uint), hence they are typed buffers. Typed buffers can’t deal with atomic operations.
Untyped buffers have their format in a descriptor that has to be loaded at runtime. This is typically stored in one or more scalar registers (SGPRs). This constant is sent to the texture cache when the fetch instruction is executed. TBOs can have arbitrary data formats that are set via OpenGL calls. Hence they’re untyped buffers. SSBOs are also untyped buffers because they must be able to handle atomic operations.
This means that TBOs must potentially use more SGPRs than UBOs; hence UBOs should always be preferred to avoid register pressure (register pressure is a big deal on GCN!). Nonetheless, OpenGL allows TBOs to be of a different format other than float or uint (i.e. half float or 8-bit uint); which dramatically reduces the bandwidth required. You should choose wisely according to your needs and bottlenecks.
Unfortunately OpenGL doesn’t have a way to explicitly define an UBO that uses half floats or 8-bit uints (since that would imply a typed buffer and half the bandwidth or less; which is best of both worlds!). You may try your luck with unpackHalf2x16 (and family of functions) by extracting 2 half floats from one uint in an UBO, and see if the driver generated the correct typed buffer fetch instruction (unfortuntely at the time of writing, GPUShaderAnalyzer for GCN doesn’t support GLSL); and cross your finger that future driver updates keep recognizing the pattern. In my opinion, this is too forced and runs on luck.
When it goes wrong, you end up fetching an uint and having additional instructions to reinterpret the data.
AMD drivers expose a limit of 2GB as maximum size for UBOs, which makes UBOs a perfect fit for most of your needs over TBOs.
You don’t believe me? Ok, here’s a simple test using HLSL and GPUShaderAnalyzer:
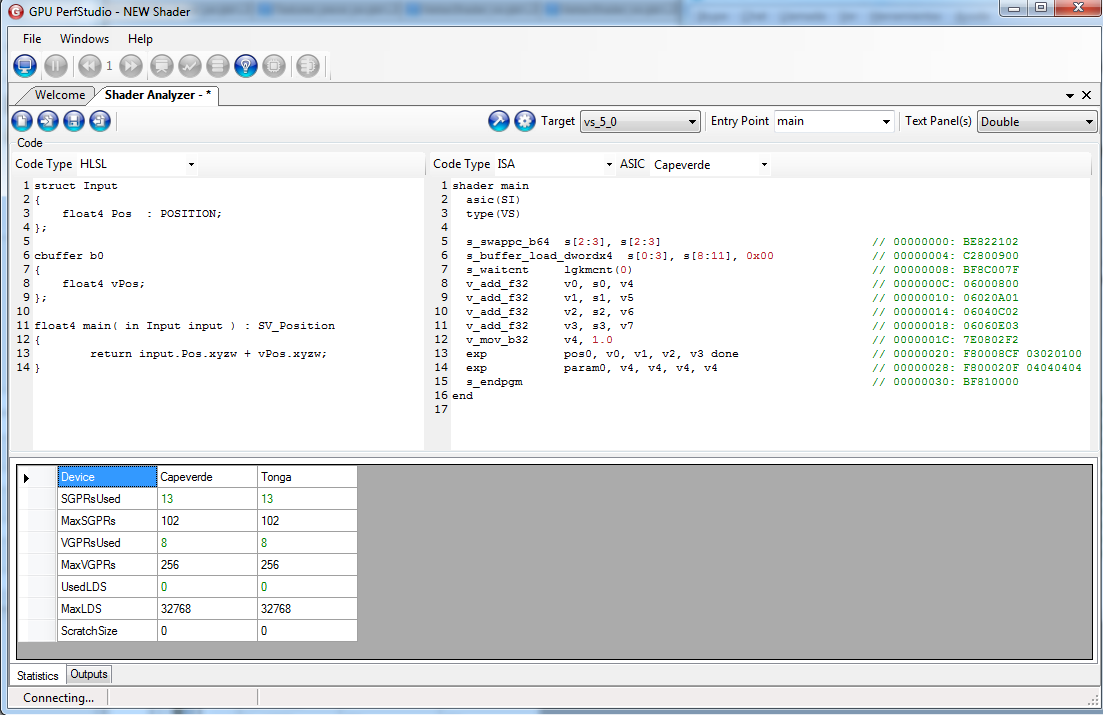
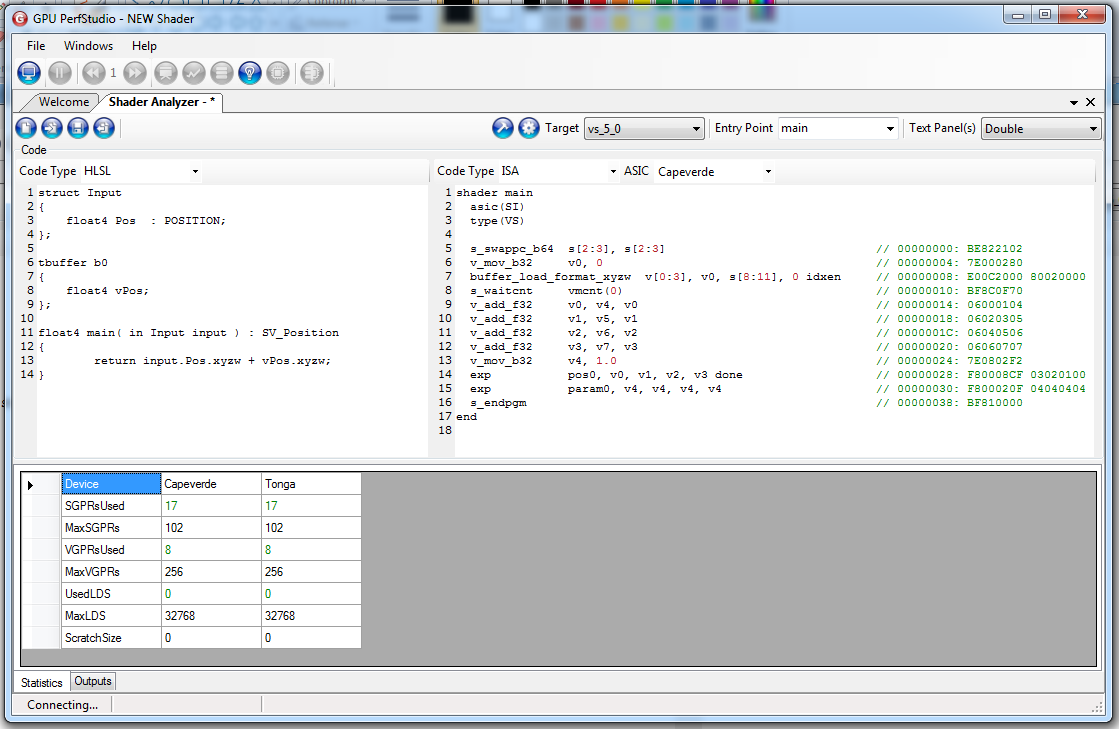
The generated ISA code is exactly the same except for:
- An additional instruction in tbuffer/tbo version “v_mov_b32 v0, 0” at the beginning. I’m not sure it’s necessary. It could be caused due to Direct3D being generating a quite different IL assembly and thus the driver wasn’t able to fully optimize the resulting ISA.
- s_buffer_load_dwordx4 vs buffer_load_format_xyzw; which is a typed load on a scalar register vs an untyped load on a vector register.
- The VGPR count is the same. The SGPR is not. The tbuffer/tbo approach required 4 scalar registers which appear to be hidden (not shown in the ISA code; unless I’m mistaken)
I wonder if untyped buffers are unable to store the loaded data in a scalar register at all, or if this is just a driver oddity.
Now let’s try a slightly more complex version, where the driver is forced to load in vector registers:
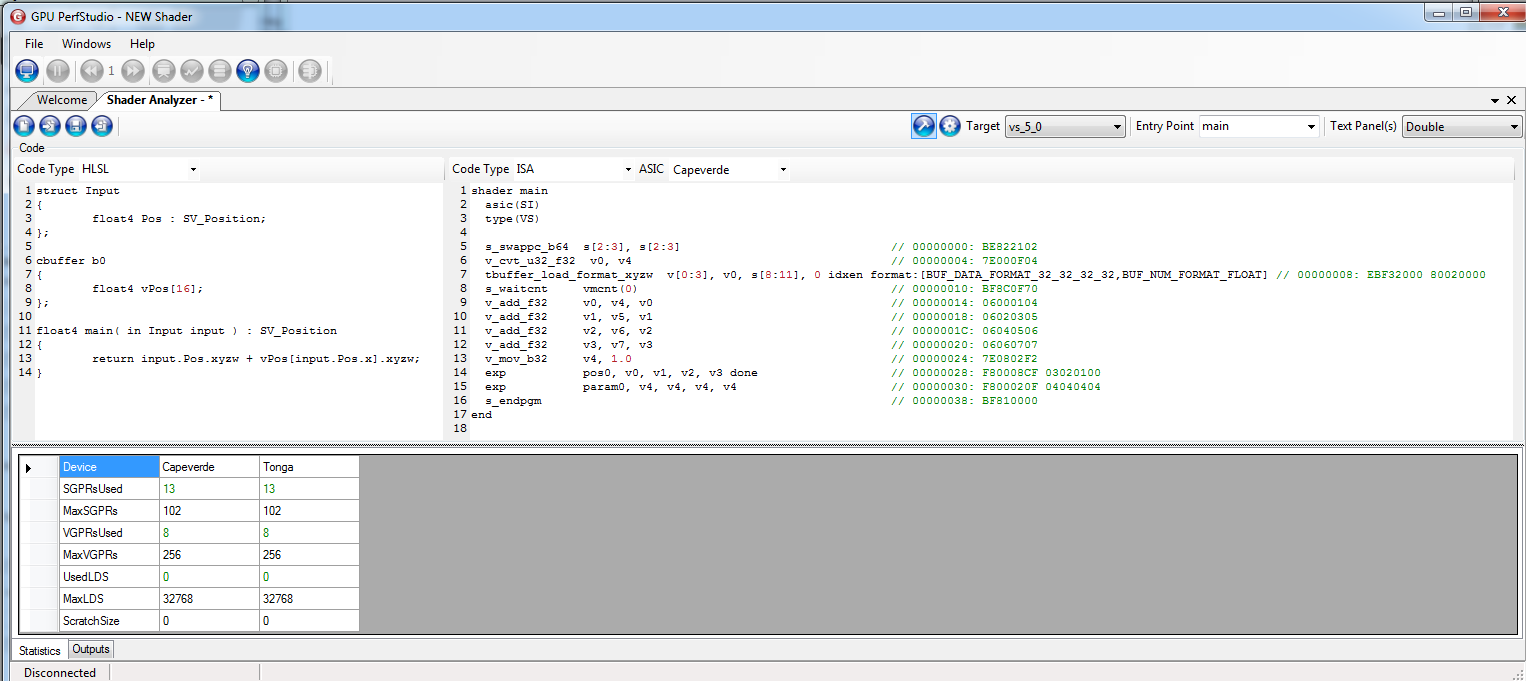
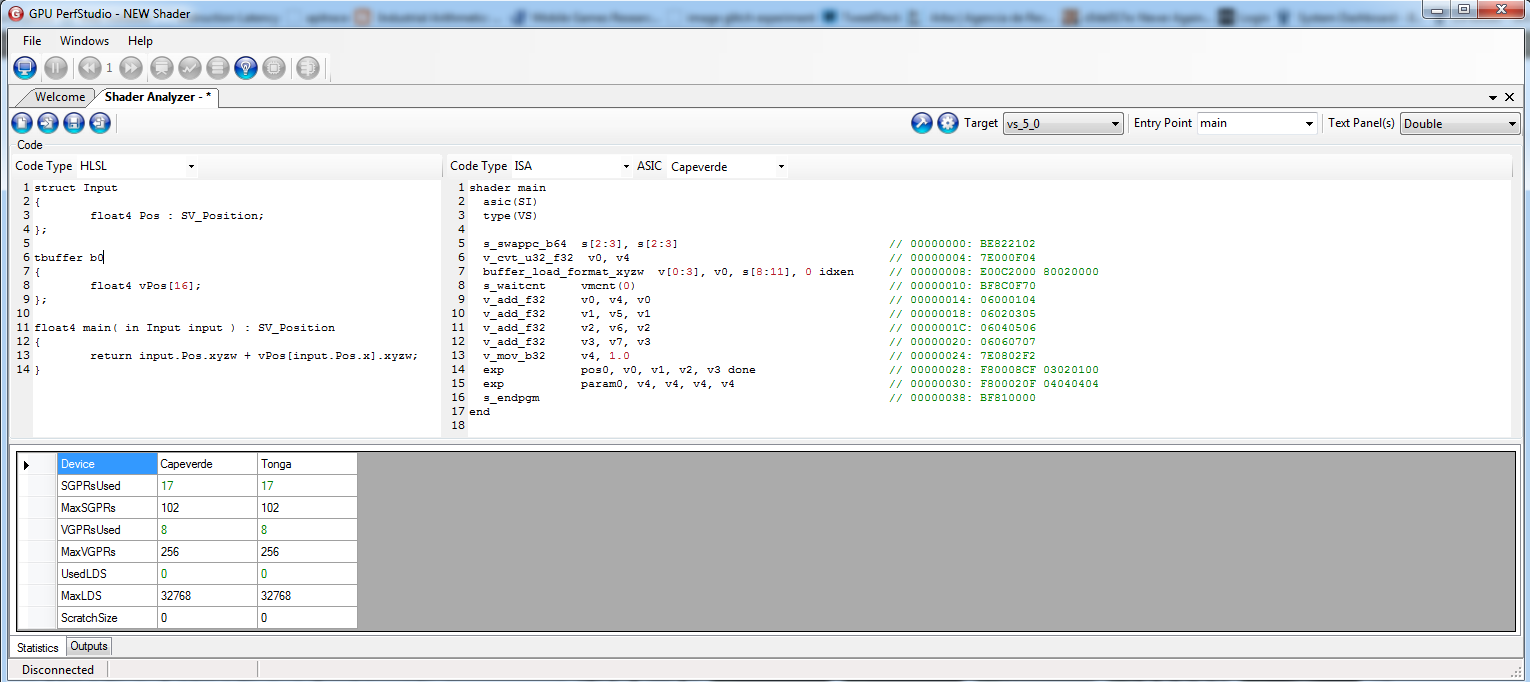
Ahh!! This one is even better. Remarks:
- The generated code is exactly the same, except for the ‘t’ for typed prefix in the buffer_load instruction (and the typed load requires to specify in which format is the data)
- Despite being the same code, the SPGR count went up by 4. Just like in the previous example.
- Further experimentation shows that additional loads to the same texture buffer, the SPGR count will stay the same. So it’s a fixed cost of 4.
- Further experimentation shows that adding more buffers (whether texture or constant buffers) won’t use 4 more SPGRs (i.e. two TBOs won’t make a total of 8). In fact, it may go down to a cost of 3 but using more VGPRs and/or additional instructions in the process. Note that VGPRs are usually more precious than SGPRs.
TL;DR: Always prefer UBO over TBO unless you’re bandwidth limited or want to use anything other than float or 32-bit ints.
For NVIDIA:
NVIDIA doesn’t share information about their hardware.
Note that NVIDIA drivers expose only 64kb as maximum size for UBOs, which can be an issue if you want to access a lot of data unless you’re willing to call glBindBufferRange every 64kb and split instancing or multidraw calls into multiple calls; thus making TBOs a better choice for reducing driver overhead.
Hopefully some NVIDIA engineer could shed some light to help us understand how to better optimize for their hardware, also help explaining why they haven’t raised the UBO limit from 64kb in their drivers (since I suspect their hardware works very similar to GCN’s, Kepler too has L1 and L2 caches)
For Intel:
Intel shares a lot of information about the hardware, but I haven’t got the time to dig through it yet.
Note that Intel drivers expose only 32kb as maximum size for UBOs, and thus shares the same issue as NVIDIA. For Intel HD 3000, the limit is even lower (16kb)
(Thanks Intel for raising this limit from 16kb to 32kb for HD 4000 series).
Final conclussions
If you’re targeting specificly the GCN (i.e. you’re lucky enough to target either PS4 or XBox One; or may be you have some sort of sponsor deal with AMD), prefer Uniform Buffer Objects for everything (i.e. sending global data, like lights and view projection matrices; to send skinning matrices; to send material BDRF propierties, etc), ; unless you’re bandwidth bound and you think you can use lower precision.
But if you’re targeting a broad number of hardware, prefer using TBOs for large datasets (i.e. skinning matrices, world-view-projection or world matrices); as one UBO can only hold between 256 (16 kb) and 1024 (64kb) 4×4 matrices for 2 out of 3 major vendors; and pick UBOs for small datasets (global data like view projection matrices, forward rendered lights).
Also remember that for older hardware (which is still a relevant market), the old limitations apply as they’re affected by Shader Constant Waterfalling.
As with everything, remember there are no absolute truths, only general guidelines and tips. GPUs are complex systems and you may find counter-intuitive examples out there in the real world. You should always profile your results.
Hi Matias, great article! Thanks for writing it.
I had previously seen tip 41 of the AMD’s GCN Performance Tweets (“Dynamic indexing into a Constant Buffer counts as fetch indirection and should be avoided.” with the added note that “If a calculated index is different across all threads of a wavefront then the fetch of Constant Buffer data using such index is akin to a memory fetch operation.”), and assumed it was related to constant waterfalling, but from your article and the added note I see that isn’t the case.
So I was wondering, do you know anything about the _actual_ cost of doing this kinds of dynamic indexing on GCN? The tip says it “should be avoided”, but it sounds to me like it — if nothing else — shouldn’t be anywhere near as bad as with older architectures and SCW. How does a normal (non-indexed) constant buffer work if it is not a “memory fetch”, and how expensive is that in comparison? I get that each thread fetching a separate value is more costly then all of them fetching the same value, but unless that is way more expensive than you’d normally assume I don’t see why AMD would publish a tip telling developers to avoid doing it?
Thanks!
Hi Christian!
It is explained in http://amd-dev.wpengine.netdna-cdn.com/wordpress/media/2012/10/GS-4106_Mah-Final_APU13_Full_Version_Web.ppsx, starting from slide 40 how the fetching works (also see perf. tip #33 and see http://developer.amd.com/wordpress/media/2012/12/AMD_Southern_Islands_Instruction_Set_Architecture.pdf page 85; then http://www.amd.com/Documents/GCN_Architecture_whitepaper.pdf page 8):
* If all threads in a wavefront access the same address, it is handled via a broadcast. This is fast.
* If all threads in a wavefront access different banks, it is fast.
* If thread A and thread B access bank X, while thread C accesses bank Y; A and B will have a bank conflict and it is slow; whether it’s ubo or tbo.
Quoting:
‘Both LDS and GDS can perform indexed and atomic data share operations. For
brevity, “LDS” is used in the text below and, except where noted, also applies to
GDS.
Indexed and atomic operations supply a unique address per work-item from the
VGPRs to the LDS, and supply or return unique data per work-item back to
VGPRs. Due to the internal banked structure of LDS, operations can complete
in as little as two cycles, or take as many 64 cycles, depending upon the number
of bank conflicts (addresses that map to the same memory bank).
Indexed operations are simple LDS load and store operations that read data
from, and return data to, VGPRs’
So there you go, according to documentation it can take from 2 to 64 cycles.
So, as long as you either: index always the same skinning matrix, or all the matrices accessed are in separate banks, it should run fast.
Also performance penalty is directly proportional to the number of conflicts. Furthermore this latency can be hidden with ALU operations. And this applies whether you’re using UBOs or TBOs.
So this isn’t exactly SCW where one single divergent thread = disaster.
Here’s a simple explanation of how bank conflicts work: http://stackoverflow.com/a/3842483
Thanks for the helpful response. 🙂
A quick follow-up re. Nvidia: I saw this article about dynamic indexing in Cuda today, which seems to indicate that non-uniform indexing to global memory (“Logical local memory actually resides in global GPU memory”) is pretty expensive because of the need to “‘replay’ load/store instructions”. That sounds suspiciously like constant waterfalling, or am I wrong? The article goes on to say that doing this is much faster when accessing shared memory, however.
Could this explain Nvidia’s limited UBO size? I.e. they place UBO-data in shared memory so that non-uniform indexing is faster than it would be if they allowed it to be placed in global memory. From this article on shared memory it sounds like 64KB is the total amount of on-chip memory on each multiprocessor.
Thanks!